伪随机数
序
伪随机性(英语:Pseudorandomness)是指一个过程似乎是随机的,但实际上并不是。例如伪随机数(或称伪乱数),是使用一个确定性的算法计算出来的似乎是随机的数序,因此伪随机数实际上并不随机。在计算伪随机数时假如使用的开始值不变的话,那么伪随机数的数序也不变。伪随机数的随机性可以用它的统计特性来衡量,其主要特征是每个数出现的可能性和它出现时与数序中其它数的关系。伪随机数的优点是它的计算比较简单,而且只使用少数数值很难推算出计算它的算法。一般人们使用一个假的随机数,比如电脑上的时间作为计算伪随机数的开始值。
产生随机数的方法
- 线性同余法
- 平方取中法
- M-Sequence
- 梅森旋转算法
- 伪随机数二进制数列
其中使用最多的是线性同余法和梅森旋转算法,下面主要介绍一下线性同余法
线性同余法(LCG linear congruential generator)
线性同余方法(LCG)是个产生伪随机数的方法。 它是根据递归公式: $$N_{j+1}\equiv (A\times N_{j}+C){\pmod {M}}$$ 其中$A,C,M$是产生器设定的常数。
Python implementation
class Random:
def __init__(self, A, C, M, seed=0):
self._A = A
self._C = C
self._M = M
self._prev = seed % M
def __call__(self):
A = self._A
C = self._C
M = self._M
prev = self._prev
cur = self._prev = (A * prev + C) % M
return cur / M
def __repr__(self):
return 'Random(A={obj._A!r}, C={obj._C!r}, M={obj._M!r})'.format(obj=self)随机数序列周期长度
 LCG产生的随机数序列周期最大为$M$,但大部分情况都会少于$M$。要使随机数序列达到最大周期,应符合以下条件:
LCG产生的随机数序列周期最大为$M$,但大部分情况都会少于$M$。要使随机数序列达到最大周期,应符合以下条件:
- $C,M$互质;
- $M$的所有质因数都能整除 $A-1$;
- 若 $M$是4的倍数, $A-1$也是;
- $A,C,N_{0}$都比 $M$小;
- $A,C$是正整数。
优点与缺点
- LCG速度非常快,需要的内存少;
- LCG不适用于需要高质量的随机数的应用,例如蒙特卡罗模拟Monte Carlo simulation;
当使用LCG生成n维空间中的点,则这些点将位于$(n!m)^{1/n}$超平面(hyperplanes);(Marsaglia's Theorem)
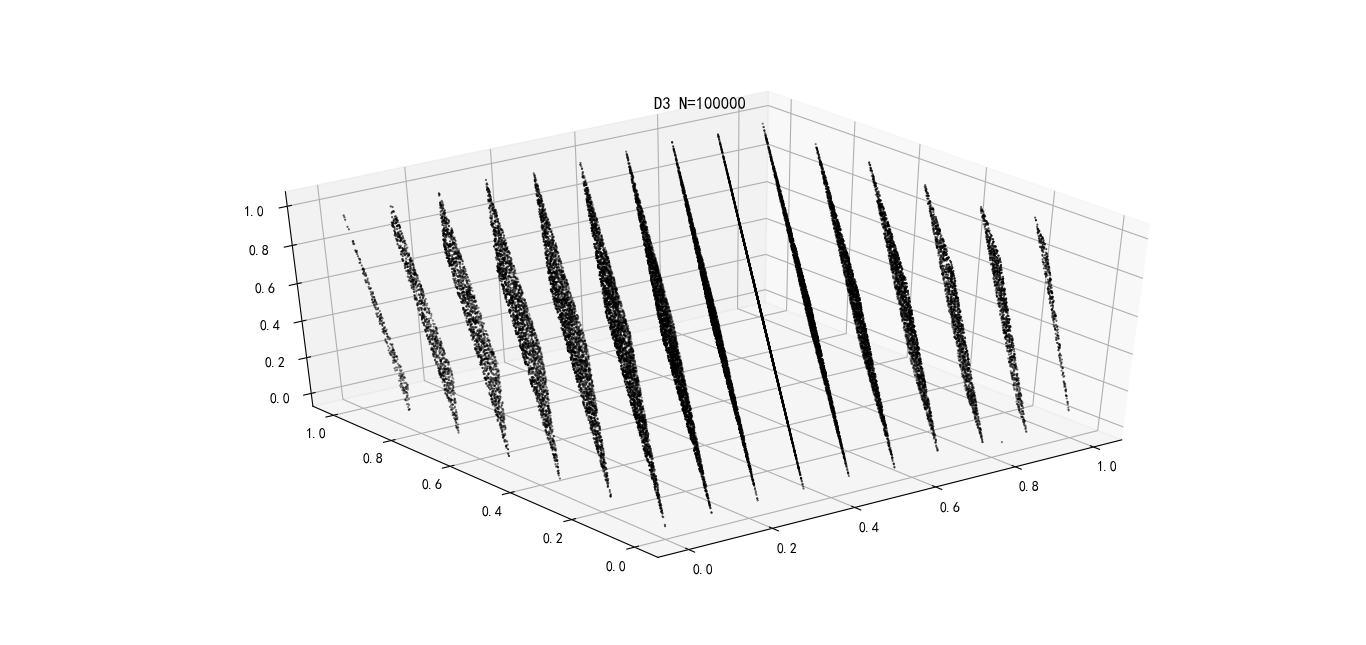
Spectral test是一种伪随机数生成器(PRNG),线性同余生成器(LCG)的生成的随机数质量的统计检验方法。 例如,使用
Random(A=65539, C=0, M=2**31, seed=1)产生100,000个随机数在3维空间上的分布。很明显,所有点只落在15个二维平面上。这是由LCG产生的随机数序列中相继值的关联导致的。
非均匀分布随机数的生成
用线性同余法可产生在$[0,1)$间均匀分布的随机数,利用反变换法Inverse transform sampling来产生非均匀分布的随机数。
均匀分布
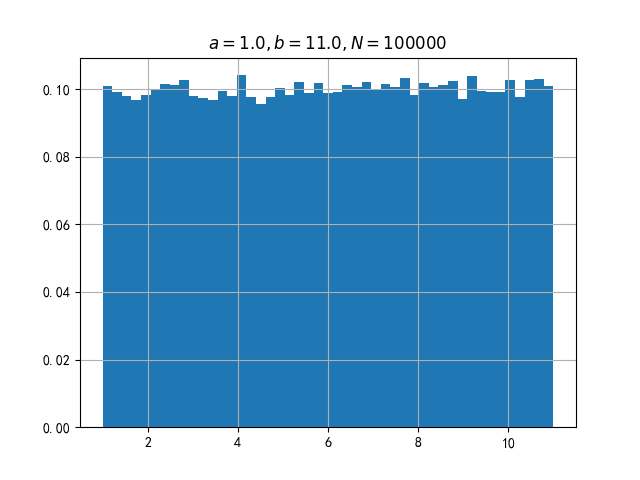
产生一个在$a\le x\le b$随机分布的随机数序列,期望的概率密度是: $$ p(x)= \begin{cases} 1/(b-a) &,a\le x\le b \\ 0 &,otherwise \end{cases} $$ 计算累积分布函数 $$ F(x)= \begin{cases} 0 \qquad &,x\lt a \\ \frac{x-a}{b-a} &,a\le x\lt b \\ 1 &,x\ge b \end{cases} $$ 计算逆累积分布函数: $$ F^{-1}(p)=a+(b-a)p \qquad ,p \in [0, 1] $$
利用上面的公式我们就可以产生符合均匀分布的随机数。这个过程就叫做反变换法。
Python implementation
random = Random(A=65539, C=0, M=2**31, seed=1)
def uniformDistributionFactory(a, b):
if a > b:
raise ValueError('a must be smaller than b')
def uniform_distribution():
p = random()
return a + (b - a) * p
return uniform_distribution概率密度图像
指数分布
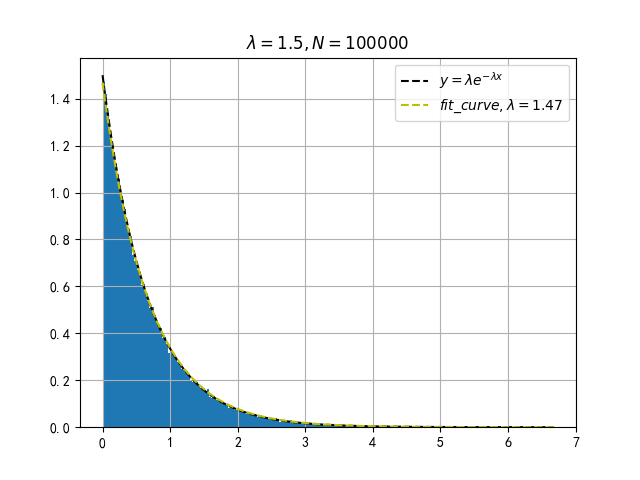
指数分布的概率密度函数为: $$ p(x)=\lambda e^{-\lambda x} ,x\gt 0 \qquad (\lambda \gt 0) $$ 计算累积分布函数: $$ F(x)=1-e^{-\lambda x} $$ 计算逆累积分布函数: $$ F^{-1}(p)=\frac{-ln(1-p)}{\lambda} $$ 利用上面的公式我们就可以产生符合指数分布的随机数。不过,因为$p$是均匀分布的,则$1-p$也是均匀分布的,所以上式可以简化成下式 $$ F^{-1}(p)=\frac{-ln(p)}{\lambda} $$
Python implementation
import math
random = Random(A=65539, C=0, M=2**31, seed=1)
def exponentialDistributionFactory(lam):
if not lam > 0:
raise ValueError('lambda must be bigger than 0')
def exponential_distribution():
p = random()
return - math.log(p, math.e) / lam
return exponential_distribution概率密度图像
正态分布
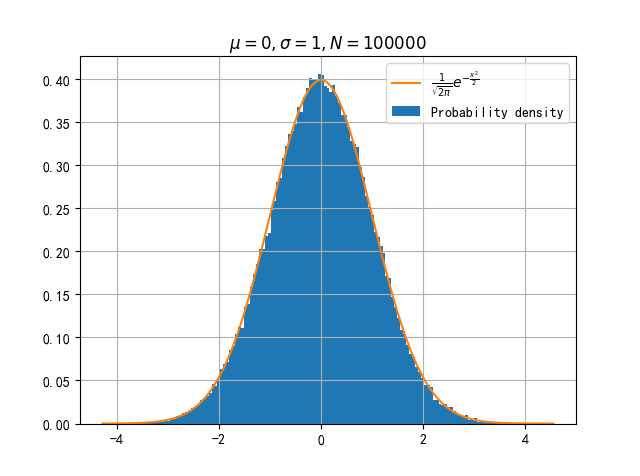
正态分布的概率密度函数为 $$ p(x)=\frac{1}{\sqrt{2\pi\sigma^2}}e^{-\frac{(x-\mu)^2}{2\sigma^2}} $$ 计算累积分布函数:
假设现在有两个独立的标准正态分布$X\sim N(0,1)$和$Y\sim N(0,1)$,由于二者相互独立,则联合概率密度函数为: $$ p(x,y)=p(x)\cdot p(y)=\frac{1}{\sqrt{2\pi}}e^{-\frac{x^2}{2}}\cdot \frac{1}{\sqrt{2\pi}}e^{-\frac{y^2}{2}} =\frac{1}{2\pi}e^{-\frac{x^2+y^2}{2}} $$
做极坐标变换,则$x=R\cos\theta$,$y=R\sin\theta$,则有: $$ \frac{1}{2\pi}e^{-\frac{x^2+y^2}{2}}=\frac{1}{2\pi}e^{-\frac{R^2}{2}} $$
这个结果可以看作是两个概率分布的密度函数的乘积,设其中一个是$[0, 2\pi]$上的均匀分布$\theta\sim Unif(0,2\pi)=\frac{1}{2\pi}$,则另外一个密度函数为: $$ p(R)=e^{-\frac{R^2}{2}} $$
计算其累计分布函数: $$ F(r)=1-e^{-\frac{r^2}{2}} $$
计算逆累积分布函数: $$ F^{-1}(p)=\sqrt{-2\ln(1-p)} $$
根据反变换法,我们可以根据上式得出符合$p®$的分布,而如果$p$是均匀分布的,则$u_1=1-p$也是均匀分布的,则: $$ X = R\cdot\cos\theta=\sqrt{-2\ln u_1}\cdot\cos (2\pi u_2) \\\\ Y = R\cdot\sin\theta=\sqrt{-2\ln u_1}\cdot\sin (2\pi u_2) $$ 利用以上任意一式即可生成符合正态分布的随机数,这个过程称作Box-Muller变换。
Python implementation
import math
random = Random(A=65539, C=0, M=2**31, seed=1)
def NormalDistributionFactory(mu, sigma):
def normal_distribution():
u1 = random()
u2 = random()
z = math.sqrt(-2*math.log(u1, math.e)) * math.cos(2 * math.pi * u2)
# z = math.sqrt(-2*math.log(u1, math.e)) * math.sin(2 * math.pi * u2)
return z * sigma + mu
return normal_distribution概率密度图像
结论
以上简单的讲了如何用线性同余法来生成均匀分布在$[0, 1)$间的随机数,再利用反变换法生成非均匀分布的伪随机数,例如指数分布,正态分布。






